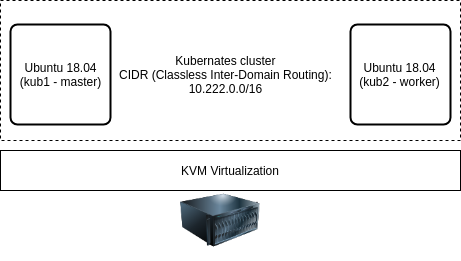
This article analyses two popular middle-ware platforms. One is High Performance middleware named Enduro/X and the other is RabbitMQ message queue. This blog will analyse them both from different technical aspects, like ease of programming, features and performance. For performance analysis sample programs will be written in both environments which will perform simple RPC (service calls) with request and reply.
The Rabbit MQ RPC code will be based on: example here.
RabbitMQ will be installed to Linux Mint 18.3/Ubuntu 16.04 according to this manual.
Test scenario
Test scenario will transport byte array of data to RPC server, the server process will transform the buffer in certain way (increment each byte by 1) and respond back to caller. The caller will measure response times. The code for both test cases will be the same. Testing will also include fault operations. For example what will happen to IPC traffic between business logic server and client in case if main admin processes of the middleware crashes. This would be critical point for fault tolerant processing. As for systems running in 24x7x365 requires ultra high stability. The IPC/RPC is performed in terms of local host. Thus showing the strength of the “open systems” programming model, where application is built from modular executables, building the client/server architecture based solutions.
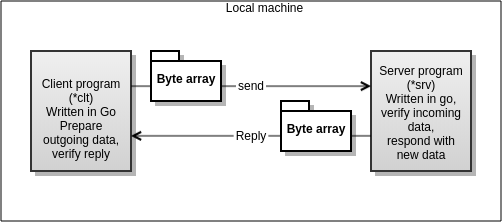
Conceptual test flow chart
The code
Common library will be built for buffer formatting, buffer verification and time measurements (and for plotting the results to results file). Language for testing is chosen Google Go lang. Reason for this, is for simplicity and better code readability. For testing Enduro/X Benchmark Suite is used. For Enduro/X test standard ATMI Client and Server is built which is two binaries. The Server is booted by Enduro/X (ndrxd) server and client process is started by process.
Startup scripts for the benchmarks can be found in “tests” directory, where
- endurox/run.sh contains the benchmark start script for Enduro/X
- rabbitmq/run.sh contains the benchmark script for RabbitMQ middleware
For RabbitMQ Go RabbitMQ Client Library is used.
Test system
Both benchmarks ar performed on following system:
- Linux Mint 18.3
- Linux 4.10.0-38-generic #42~16.04.1-Ubuntu SMP Tue Oct 10 16:32:20 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
- CPU: Intel(R) Core(TM) i5-4300U CPU @ 1.90GHz
- RAM: 12GB
Benchmark results
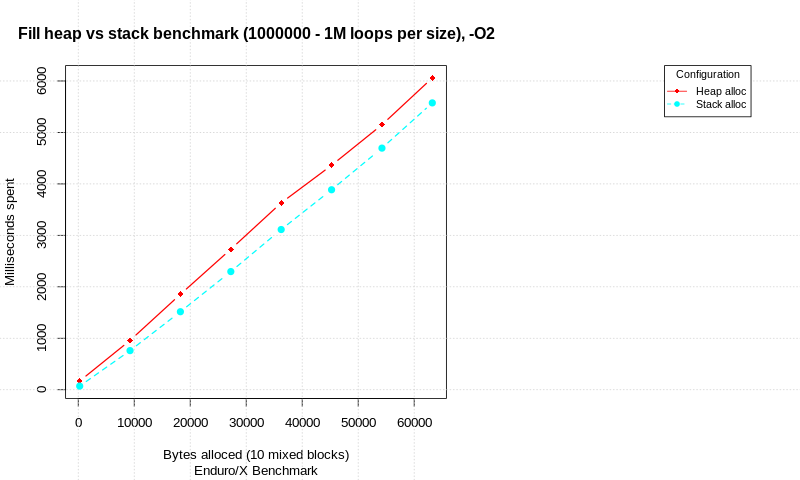
Both benchmarks are started with 40000 loops per message size, and then the loops are divided loop step with is 1..128. The message size is made as loop * 32 bytes, thus the final size is 4 KB. The special case is tested with first message, it is tested as single byte transfer.
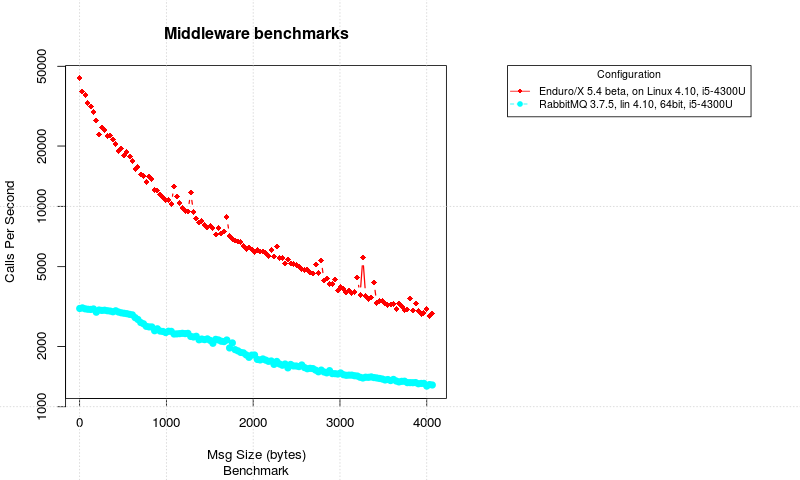
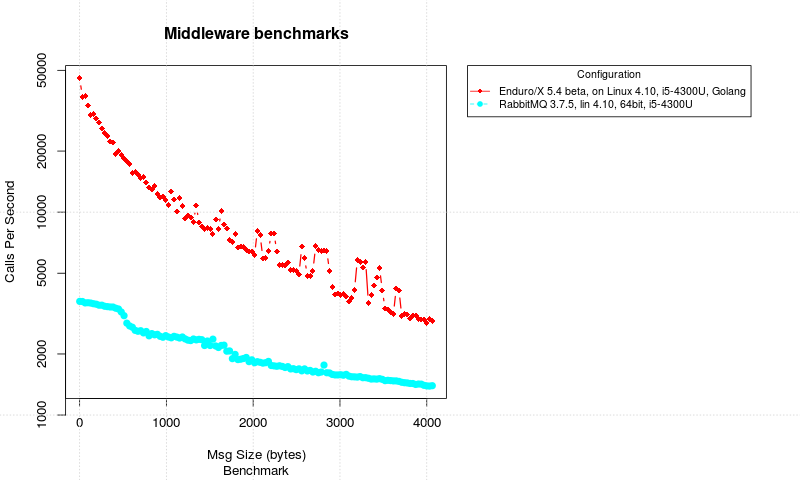
Enduro/X VS RabbitMQ RPC Messaging between Client/Server processes
Also note that Y axis of the picture is logarithmic, to give better visibility of the both system performance.
From the results it could be seen that Enduro/X Middleware is heavy ahead of the RabbitMQ. It start off with with ~ 40’000 calls per second, while only at 2.5KB it drops bellow the 5000 calls per second. While the RabbitMQ starts off with 3000 calls per second and drops till 1300 calls per second. Mean Enduro/X at 4KB is around the 2800 calls per second.
Thus from this benchmark we could see that Enduro/X is several times faster that RabbitMQ used with Go language.
CPU Usage
To better understand what is happening in the system during the tests (how much resources are utilized), lets look at the Unix “top” utility and lets see what does it shows.
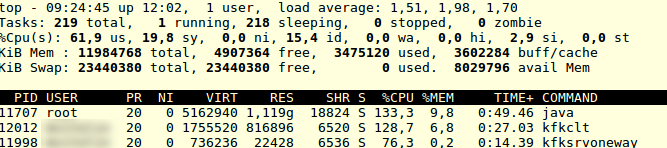
RabbitMQ CPU Usage
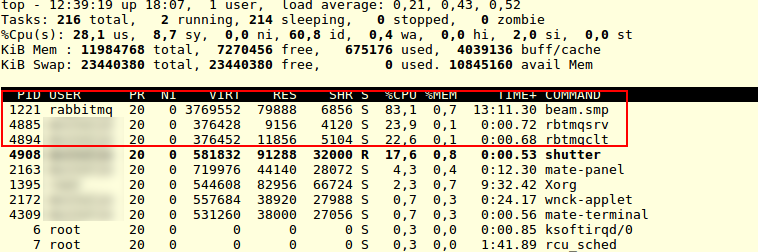
CPU Usage during RabbitMQ Testing
What the TOP shows up is that our binaries like “rbtmqsrv” ad “rbtmqclt” ar both working, but it seems that we have a “man in the middle” which is RabbitMQ by it self. Showing high numbers of CPU usage of process named “beam.smp” from rabbitmq user. Thus the total CPU usage is about 128%. The lower results of the RabbitMQ probably are given by the architecture it self – RabbitMQ uses sockets for IPC. And there is no direct IPC between two processes, but we have a “beam.smp” in the middle. To the data transport has to be done between client -> rabbitmq server -> server and vice versa. Thus it gets additional transport step.
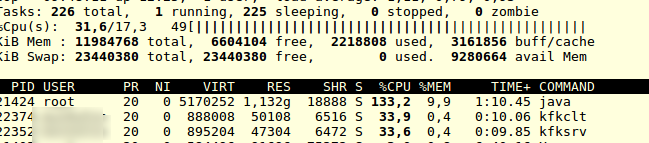
Enduro/X CPU Usage
Lets see how Enduro/X acted during the testing (note that screenshot was taken when the test was somewhere in the middle about 1-2 KB message size.)
Enduro/X CPU Usage during the test
was with lower message size “exclt” was even taking about 120% CPU. This is probably related with fact that at lower message sizes, the kernel IPC takes less role than local Golang processing.
Thus at average message size about 1-2 KB, the total processing takes about 100 %. This is logical, because half work is done in one process (client) and other half is done in server side, while to other side is sleeping (waiting for response). Client process has some more work to do, as it prepare the original request buffer.
High Availability tests – main app server
For mission critical systems all thinks might happen, for example, some daemon process might die with some process bug, out of the disk space, accidental kill (less likely), etc. in this tests we will see what will happen to our traffic when say application server “main” process will die. For Enduro/X it is “ndrxd” which boots up all the processes and manages their lifetime. For RabbitMQm, from benchmark tests authors sees that significant role takes the “beam.smp” process, thus lets try to kill it during the IPC testing.
Enduro/X HA
After killing the “ndrxd” process:
$ ps -ef | grep ndrxd
<hidden> 5206 1 0 12:40 pts/1 00:00:00 ndrxd -k 0myWI5nu
<hidden> 8123 4314 0 13:03 pts/0 00:00:00 grep --color=auto ndrxd
$ kill -9 5206
We see that program continues with out any problem:
$ top
KiB Mem : 11984768 total, 5765948 free, 1986776 used, 4232044 buff/cache
KiB Swap: 23440380 total, 23440380 free, 0 used. 9367756 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
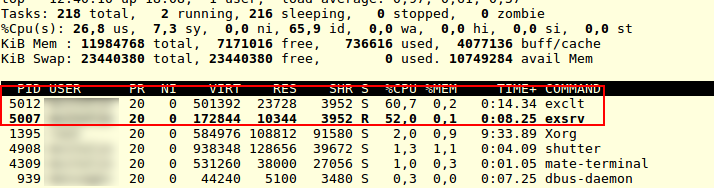
8096 <hidden> 20 0 575716 31352 3964 S 65,1 0,3 1:48.89 exclt
5208 <hidden> 20 0 238380 10244 3848 R 50,5 0,1 2:14.30 exsrv
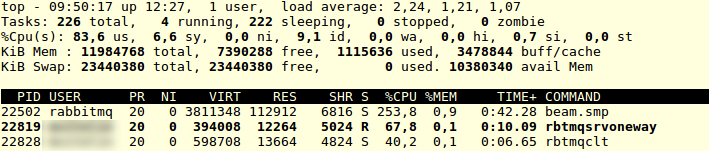
RabbitMQ HA
Now lets try with RabbitMQ. Test started situation:
$ top
top - 13:06:12 up 18:34, 1 user, load average: 0,96, 0,83, 0,64
Tasks: 227 total, 1 running, 226 sleeping, 0 stopped, 0 zombie
%Cpu(s): 25,6 us, 8,5 sy, 0,0 ni, 63,7 id, 0,0 wa, 0,0 hi, 2,1 si, 0,0 st
KiB Mem : 11984768 total, 5787076 free, 1966980 used, 4230712 buff/cache
KiB Swap: 23440380 total, 23440380 free, 0 used. 9388964 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1221 rabbitmq 20 0 3769552 79692 6856 S 87,7 0,7 13:50.11 beam.smp
8435 <hidden> 20 0 466616 11900 4628 S 25,9 0,1 0:01.04 rbtmqsrv
8444 <hidden> 20 0 376648 12808 5364 S 24,3 0,1 0:00.98 rbtmqclt
Now lets try to kill the “beam.smp”:
$ sudo kill -9 1221sudo kill -9 1221
test finishes with error:
$ ./run.sh $ ./run.sh ~/projects/endurox-benchmark-suite/tests/rabbitmq ~/projects/endurox-benchmark-suite/tests/rabbitmqStarting server process...panic:
runtime error: index out of range
goroutine 1 [running]:exbench.Ndrx_bench_verify_buffer(0xc42000e030, 0x0, 0x0, 0x0, 0x20, 0xfe, 0x6282d9, 0xe, 0x0) /home/<hidden>/projects/endurox-benchmark-suite/src/exbench/testutil.go:85 +0x35dexbench.Ndrx_bench_clmain(0xc42000e030, 0x1, 0xc42005fea8, 0x1d) /home/<hidden>/projects/endurox-benchmark-suite/src/exbench/testutil.go:195 +0x21cmain.runbench(0x0)
/home/<hidden>/projects/endurox-benchmark-suite/src/rbtmqclt/rbtmqclt.go:85 +0x320main.main() /home/<hidden>/projects/endurox-benchmark-suite/src/rbtmqclt/rbtmqclt.go:140 +0xd7rbtmqclt -num 40000 failed
Test exiting with: 2
Thus we see that for RabbitMQ the application server processes are critical for operations, if any thing happens, the real-time IPC traffic is broken.
High Availability tests – multiple consumers
The typical case for high availability processing is scenario where multiple consumers (server processes) are waiting for the message. And if any thing happens to one consumer process, the whole system is not destroyed, but maybe one transaction is lost. To test this scenario, the Enduor/X Benchmark suite will be adjusted to allow the retries of the messages (we will allow number of retries for the calls). So we will simulate typical HA test case, when one of the server processes dies and the other takes over. Visually this looks like
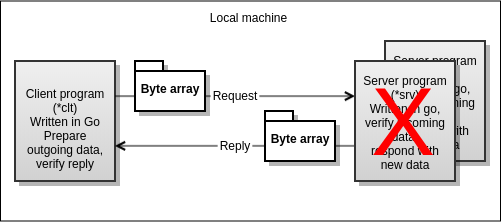
HA Test scenario with multiple consumers processes
As for Enduro/X the configuration will be changed like this in “ndrxconfig.xml”:
<server name="exsrv">
<min>2</min>
<max>2</max>
<srvid>2100</srvid>
<reloadonchange>y</reloadonchange>
<sysopt>-e ${NDRX_APPHOME}/log/exsrv.log -r</sysopt>
<cctag>1</cctag>
</server>
The min/max is set to 2 meaning that two copies of the “exsrv” is booted. They automatically operate in load balanced mode (consuming the same services which they advertise)
For RabbitMQ test, we update the test script with two server startup (see “ldbalrun.sh”):
echo "Starting server proceses... 1"
rbtmqsrv &
SV1_PID=$!
echo "Starting server proceses... 2"
rbtmqsrv &
SV2_PID=$!
sleep 1
if ! kill -0 $SV1_PID > /dev/null 2>&1; then
echo "RabbitMQ server 1 not started! Is RabbitMQ booted?" >&2
go_out 1
fi
if ! kill -0 $SV2_PID > /dev/null 2>&1; then
echo "RabbitMQ server 2 not started! Is RabbitMQ booted?" >&2
go_out 2
fi
When performed the kill for one of the “rbtmqsrv”, the test continued with no problem. Thus RabbitMQ server processes can be load balanced with high availability property.
Now lets test the Enduro/X.
Two servers are booted:
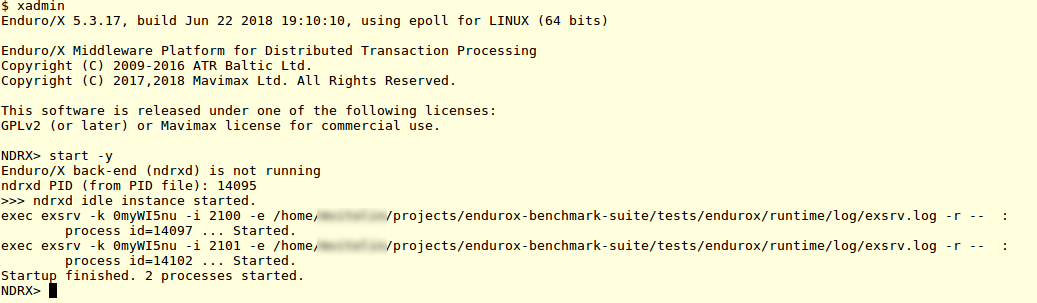
Enduro/X App server boot
Server executable statues:
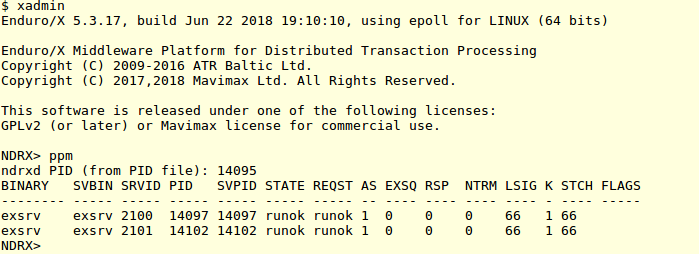
Enduro/X Process statuses at the start of the test
two processes are up and running with “66” sanity step from last status change. Now lets start the test, and kill one of the programs. The status change step shall be reset, and lets see what will happen with actual test (note the version seen in pictures here are actual staging 5.4 beta version). So after the kill, Enduor/X will reboot the missing process, thus we git following chronological picture of the process statues:
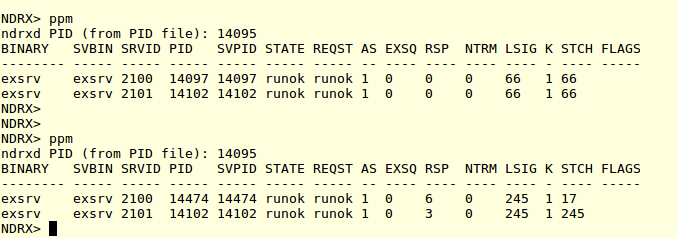
Enduro/X process statuses after the kill of one of the server processes
As we see the PID 14097 was killed and 14474 now we get in place. The test continues and there was no interruption for the client process running the benchmark (except the possible retry). By doing more “kill” to server processes, author got in client logs:
N:NDRX:2:d5d3db3a:14802:7fe243e01880:000:20180623:135940867:tpcall.c:1016:_tpgetrply to EXSVC failed
Message, while the all process was stopped. This was due to kill was reaching one of the servers while the call was in progress. Thus the client go timeout after the configured NDRX_TOUT=90 seconds of waiting for answer. Then the retry did kick in and test continued.
Update 24/06/2016 – midsummer test 🙂
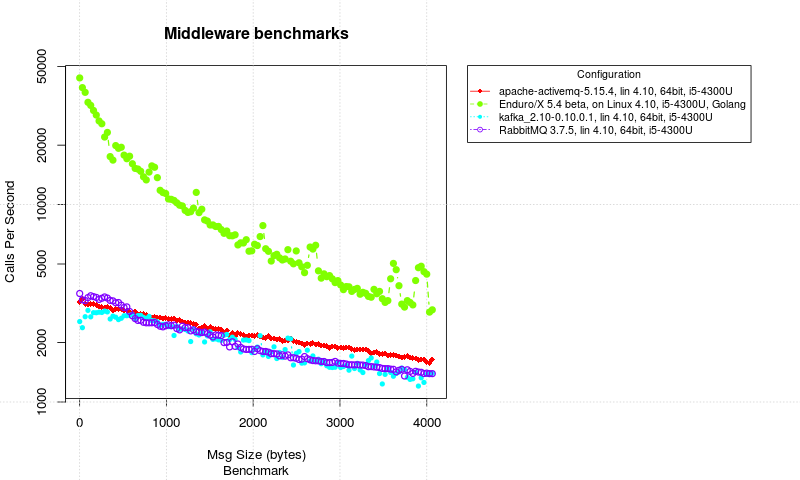
For the RPC test case to be more fair, the Auto-Ack was turned on for the RabbitMQ, thus avoid some IPC rountrip for Acking to the RabbitMQ server. The results are following (note the Enduro/X test case was re-run too, so there might be some deviation in the system performance too)
RPC benchmark with RabbitMQ Auto-Ack server set.
So with test, the RabbitMQ performed little bit better, the initial performance was 3632 RPC calls per second.
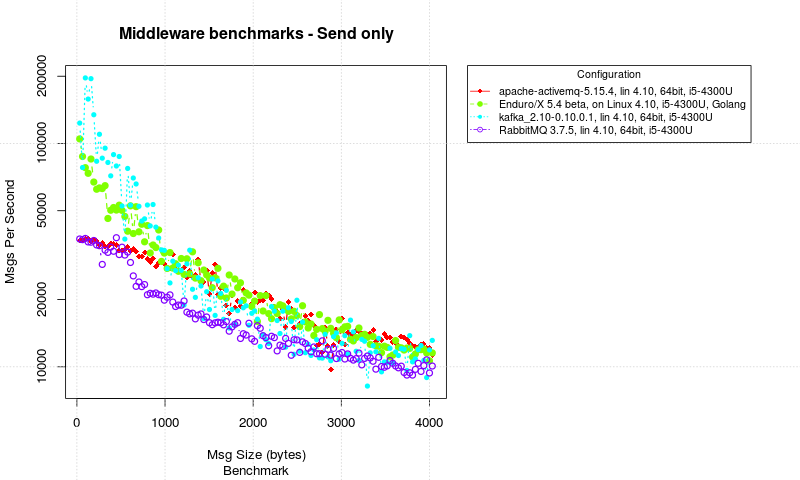
One Way call (send only, client -> server)
Another test was performed where send only messaging was done. The client streams messages to server. In this test the results are measured by server process by checking the moment when message size changes. Once changed, it divide number of messages received by time spent. Note that for each test one message is taken from next size group. Thus results is not 100% accurate, but generally the size increase is small, and message count is large, thus the measurements for compare should be fine. The results are following:
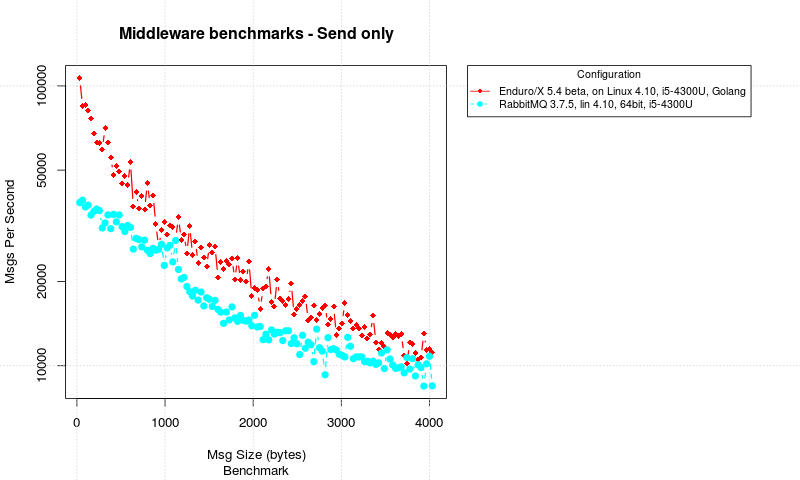
One way message delivery
In these test cases we see that Enduro/X starts about twice as fast as RabbitMQ. But numbers are good for both systems. But Enduro/X keeps RabbitMQ ahead with all message sizes. But really as surprise, RabbitMQ did hold good performance.
Conclusions
For the Go language endurox-go package did show the strength for the performance, where for small messages it was a magnitude ahead of the RabbitMQ. When message size increased the Enduro/X was several times after than RabbitMQ. This fact is critical for mission critical sub-millisecond systems, where the speed of might split the deal (for example Forex Exchange systems).
From high availability perspective regarding to the HA of the Application Server by it self, Enduro/X also here showed the strength in fact that the death of the App Server by it self, did not cause IPC traffic to be interrupted. While the death of the RabbitMQ server, did cause IPC to stop. For the systems which run for 24x7x365, this fact is critical. Also according to the Enduro/X tprecover process documentation, the “ndrxd” process is full recoverable, thus the business process will not see the any changes or interruptions.
The third test for load balanced/high availability server processes, the test confirms that for both systems like Enduro/X and RabbitMQ, the death of the load balanced server process does not cause the IPC problems and system can continue to live with other copy left from the multiple server processes.
For the Send only messages, both systems performed well, and by the surprise the performance numbers for RabbitMQ was good, but still Enduro/X did outperform the RabbitMQ.